Por Juan Germán Gayoso Arnillas – Icónica Gestión.
Tags: Real Estate, Alquiler, Ratios, ASEI, Lima Metropolitana.
Resumen y problema a resolver
Si, son una buena y mejor alternativa a aplicar el precio promedio como método de cálculo para estimar el alquiler de departamentos. Si, aunque supongan un proceso más trabajoso de cálculo generan un método que permite tomar en cuenta múltiples parámetros que contribuyen a un cálculo consistente y que refleja de manera más ajustada a lo real.
El mercado de alquiler de departamentos es una fuente importante de información de la salud del desarrollo inmobiliario, al poder desarrollar indicadores de tiempo medio de pago de una inversión y compararla con los kpis que historicamente han definido la salud de los mercados de desarrollo[1].
Del mismo modo, la información de alquiler de departamentos y su variación temporal permite tener un entendimiento del mercado de inversión, al poder evaluar que productos se mantienen en stock en mayor proporción y cómo se relacionan con el segmento al que están enfocados en cuanto a su dimensión y precio.
Sin embargo, los análisis que se pueden realizar con la información disponible son engorrosos, debido a la falta de plataformas con datos ordenados e indexados, por lo que es necesario el uso de herramientas de procesamiento de lenguaje para extraer la información de las descripciones de las unidades. Esto se evidención en el post pasado sobre un estandar de nomenclatura en las unidades en venta y alquiler[2].
Con modelos paramétricos consistentes es posible estimar rápidamente los precios y con ello tener información objetiva al instante sin recurrir a generalizaciones como el precio promedio.
Información recabada y características de la oferta.
Se tomaron los datos de alquiler de las propiedades de Lima Metropolitana, extrayendo información de los portales de alquiler en línea que hay para el mercado local.
En total se pudieron extraer un total de 13mil propiedades de Lima y provincias.
Depurando solo los de Lima y Callao se tiene esta distribución de frecuencias de la cantidad de muestras de propiedades por distrito:

De esta manera se puede acotar el modelo a aquellos distritos que tienen una mayor muestra y evitar la distorsión de aquellos que no tienen datos para una correcta regresión.
Del mismo modo se eliman los departamentos ubicados en las playas de Lima y Cañete, dado que estas tienen un precio de alquiler basados en características o criterios distintos a los de vivienda, al ser estacionales.
Una última depuración es de aquellos distritos donde la cantidad de propiedades en alquiler son menores a 10 unidades.
Preparación del modelo paramétrico
Se hizo un modelo simplificado de los departamentos de Lima y Callao con la finalidad de hacer un modelo lineal de múltiples parámetros para la estimación de los precios de los departamentos.
Se tomaron en consideración los siguientes parámetros:
- Distrito
- Area total del departamento.
- Indicación de si está o no amoblado
- Cantidad de dormitorios.
- Cantidad de baños.
- Cantidad de estacionamientos.
Existen parámetros adicionales que podrían dar mejor ajuste al modelo, tales como, urbanización, NSE de la zona, pero de manera preliminar y debido a la dificultad en limpiar la información se iniciará el análisis con las variables descritas.
Es importante la estandarización, tal y como se escribió en un post anterior, dado que las descripciones de los departamentos incluyen frases coloquiales y muy variables que impiden extraer las características objetivas de las unidades, de tener variables en la base de datos que indiquen los parámetros adicionales que se plantean sería más rápido el estudio.
Si aplicamos una nube de palabras sobre la información de descripción de las unidades se tiene lo siguiente:

Varios de los conjuntos de palabras que más repetición tienen son descripciones coloquiales de las unidades y su ubicación, esto no aporta valor al análisis y más bien imposibilita determinar facilmente la información cualittiva de la unidad, como por ejemplo si esta está amoblada o no.
Para poder determinar si las unidades estaban o no amobladas fue necesario hacer un análisis sobre la raíz de la palabra amoblar y con ello depurar en el texto aquello que define a la unidad como amoblada.
Para poder limpiar la información se ha utilizado regular expressions utilizando Google sheets y también una limpieza preliminar con Open Refine para uniformizar la base de datos. Con todo esto se ha generado un archivo CSV con la base de datos de Lima Metropolitana.
Para evitar la correlación a priori que hay entre el ratio de alquiler por metro cuadrado y el área total del departamento, se está dejando de utilizar como variable dependiente dicho ratio y se pasará a utilizar el precio de alquiler total llevado a dólares con un tipo de cambio de 3.6 soles por dólar.
Como se mencionó se ha hecho una reducción de la muestra a aquellos distritos que mayor cantidad de propiedades tienen, por lo tanto se tomará la siguiente información en el análisis.

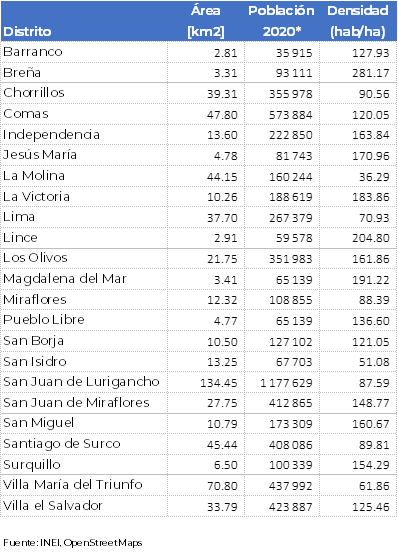
A manera de resumen de sus precios de alquiler por m2 en dólares se tiene la siguiente tabla, donde el rango dado por -2s y +2s representa el intervalo donde cae el 95% de las muestras de cada distrito.

De manera gráfica se tiene esta distribución:

La gráfica muestra en el eje vertical izquierdo la cantidad de propiedades en oferta en cada distrito, representadas por las barras azules, mientras que el ratio de alquiler de USD/m2 está representada por cuatro variables, los extremos máximos y mínimos de los distritos y en la caja blanca el rango definido por +- 2s que enmarca, en una distribución normal, el 95% de la totalidad de las muestras de los distritos.
Si requirieramos hacer una estimación rápida es posible utilizar estos rangos y con ello tener una magnitud del alquiler de un departamento en los distritos analizados.
Tratamiento de las variables.
Cantidad de dormitorios
Para poder analizar los dormitorios se tiene el siguiente gráfico de frecuencias.

En vista que la mayor frecuencia se tiene en departamentos de 1, 2 y 3 dormitorios se trabajarán con una variable de agrupación, en la que estén separados estas tres variantes y la de 4 a más en una variable. Todas ellas se tratarán como dummies binarias.
Cantidad de baños

De la misma manera que en los dormitorios, se tomarán como clases independientes los grupos de 1, 2, 3 y 4 baños, para los 5 a más se tendrá un grupo único.
Cantidad de estacionamientos

Con respecto a los estacionamientos el grupo se simplificará un poco más, siendo grupos independientes los de 1 y 2 estacionamientos y 3 a más serán un paquete.
Con estas premisas se rehace el modelo de alquileres manteniendo la muestra con todos los distritos.
De esta manera se probará si el modelo de regresión lineal tiene un mejor ajuste y permite estimar de manera más acertada los montos de alquiler.
Modelo paramétrico
Para generar el modelo se empleará tanto el software R como Gretl, comparándose los modelos resultantes de ambos programas y el ajuste de la regresión que propongan con respecto a la muestra.
Modelo paramétrico en Gretl
Bajo un modelo de mínimos cuadrados ordinarios el software Gretl genera un modelo con las siguientes características:

Las variables independientes empleadas tienen correlación con la variable dependiente en todos los casos y el ajuste del modelo con la muestra llega al 79.26% de la muestra.
Si se grafican los valores observados versus los valores proyectados de la curva de regresión se tiene la siguiente superposición, donde las barras verdes representan la muestra de precios de alquiler y las barras naranjas los valores estimados con el modelo de regresión para los mismos parámetros de cada muestra:

Se puede apreciar un ajuste sobre los valores de mayor representación, sin embargo, aquellos valores extremos no son calculados adecuadamente.
Por lo tanto, si se requiere la estimación del precio de alquiler de un departamento en los distritos descritos en el modelo es posible utlizar los coeficientes calculados y con ello tener una estimación del precio de alquiler en dólares americanos.
Por ejemplo, si requerimos estimar el precio de alquiler de un departamento en Miraflores de unos 210 m2 de 03 dormitorios, 03 baños y 02 estacionamientos no amoblado, tendremos un valor de alquiler de USD 1’927.60 o en su defecto un ratio por m2 de 9.18 USD/m2.
El cálculo está dado por la siguiente ecuación:
Value_USD= 7.62*Area_Total+ 732.33*Miraflores- 11.6*Dormitorios_3+ 53.48*Banios_3- 447.72*Estac_2
Modelo paramétrico en R
En R se utilizó el modelo lineal de regresión considerando las mismas variables que en Gretl.
En este modelo se tuvo el siguiente resultado:

En el modelo lineal de R se tiene un ajuste del 79.26% igual al 79.26% que se tiene en la regresión de Gretl.
Si se grafican los valores observados versus los valores proyectados de la curva de regresión se tiene la siguiente superposición, donde las barras verdes representan la muestra de precios de alquiler y las barras azules los valores estimados con el modelo de regresión para los mismos parámetros de cada muestra:

En ella se puede apreciar que la predicción del modelo se ajusta con los valores que representan a la mayor cantidad de observaciones, sin embargo, aquellos valores extremos no pueden ser estimados por la regresión de manera adecuada.
Para el mismo ejemplo de un departamento en Miraflores de 246 m2 con 3 dormitorios, 3 baños y 2 estacionamientos sin amoblar se tiene un precio de alquiler de: 1927.60 USD o en su defecto un ratio por m2 de 9.18 USD/m2. Siendo equivalentes las dos estimaciones entre Gretl y R.
El cálculo esta dado por la siguiente ecuación.
Valor_USD= 361.56+ 7.62*Area_Total+ 370.77*Miraflores-11.6*Dormitorios_3+ 53.48*Banios_3- 447.72*Estac_2
Conclusiones
La información del mercado de alquiler puede recabarse de los distintos portales de internet, pero pese a esta disponibilidad debe trabajarse previamente para limpiar la información debido a que no hay un estándar para describir las características cuantitativas y cualitativas de ellas. El uso de un estándar en el gremio inmobiliario permitiría tener información homogénea para análisis de este tipo, incluyendo variables temporales y correlaciones con la venta de unidades nuevas de una manera más rápida.
El modelo líneal de regresión genera un ajuste del 80%, lo que lo hace útil para la estimación del precio de alquiler de departamentos. A su vez, las variables dependientes definidas en el presente estudio explican en el comportamiento del precio de alquiler en dicho porcentaje, son por lo tanto lo que define el valor de una unidad.
El uso de modelos de estimación paramétricos genera información rápida, consistente y confiable que ayuda al análisis de los negocios inmobiliarios, al tener precios de alquiler rápidamente para las posibles inversiones y con ello hacer cálculos sobre el beneficio de una inversión.
Con el uso de modelos de estimación paramétrica en las propiedades en alquiler se abre una ventana para la extrapolación del método en los departamentos en venta, lo que da la posibilidad de tener un modelo que tome parámetros más detallados de las características de las unidades, del edificio y del entorno donde se encuentra este.
[1] https://www.globalpropertyguide.com/Latin-America/Peru/price-rent-ratio
[2] https://piensoluegocambio.wordpress.com/2020/06/11/estandar-de-nomenclatura-de-departamentos-para-el-mercado-inmobiliario/